
本篇 Python 文章將帶領你們進入爬蟲程式的入門與實作,並以591房屋交易網為實作,591服務條款已有聲明如(下圖),本篇文章僅作教學範例使用,實作本範例純屬個人行為,本作者不負任何法律責任,會撰寫本篇文章主要用意為拋磚引玉,讓任何有興趣學習的讀者有好的教材可以入門,程式軟體本身並沒有好壞之分,完全取決於使用者的目的,我們要尊重智慧財產權,這是最基本的互相尊重。

Python 爬蟲本文正式開始,首先假設情境,5個步驟解析需求和解決辦法
先設想,若要開發一個完整的 python 程式軟體,需要將需求條列出來並搭配解決的方法,可以在製作上更流暢的製作以及邏輯的規劃。我們假設今天老闆要求我製作一個591的爬蟲軟體並要能夠將資料匯出成EXCEL以利後續的資料應用,再次強調!當然前提是已經取得591明確的授權才能這樣使用,否則遭受法律上的追究。
- UI/UX設計:採用 tkinter 套件設計
- 使用者的驗證邏輯:例如使用者的裝置授權數量或是驗證碼的製作,採用 firebase 做簡易資料庫做資料比對
- 網頁資料抓取:採用 selenium 將對應的物件抓取出來後用 BeautifulSoup 套件將資料取回應用
- 彙整取回資料:將網頁上所有的資訊整理
- 製作輸出格式:採用 pandas 以及解決遇到的困難,如電話號碼欄位是圖片,我們透過 pytesseract 套件將圖片轉成文字以利輸出後透過 styleframe 輸出成 EXECL
有了以上初步的規劃後,就能夠一步一步具體的達成目標,當然並不是每所有預先想到的解決辦法都能夠完美克服困難,這正是寫程式的樂趣所在,遇到困難想辦法解決,每一次都在提升自己的功力。
1. Python UI/UX設計:採用 tkinter 套件設計
坦白說,UI/UX這塊並不是我的專業所在,我沒辦法帶領大家設計出很漂亮的視窗,還請各位讀者見諒,初步規劃如下
- 驗證碼:想要能夠掌控使用者的使用狀況,可以理解成登入的帳號
- 類型:591內有許多的類型如新建案、中古屋、租屋、店面、辦公、廠房土地等等
- 縣市/區域:限制資料的縣市/區域,以及最後確定縣市/區域的按鈕
- 程式運作的對話框,讓使用者知道目前程式運作的情況
- 最後,最重要的聲明連結
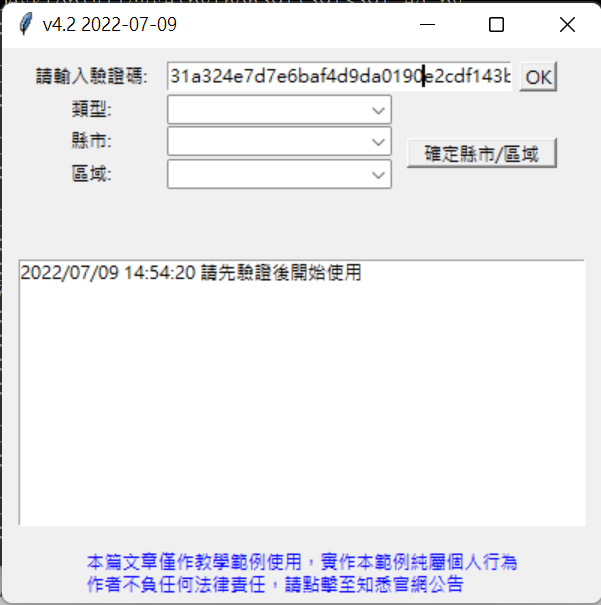
UI/UX設計部分程式:
// 製作視窗大小
window = tk.Tk()
window.title(VERSION + ' ' + str(now_today))
window.geometry('400x370')
// 請輸入驗證碼提示文字
labVerify = tk.Label(window, text = '請輸入驗證碼:', justify=tk.RIGHT, width=50)
labVerify.place(x=10, y=9, width=100, height=20)
// 驗證碼輸入框
varVerify = tk.StringVar()
varVerify.set('')
entVerify = tk.Entry(window, width = 120, textvariable = varVerify)
entVerify.place(x=110, y=9, width=230, height=20)
// OK按鈕
btnVerify = tk.Button(window, text='OK', width=100, command=VerifyCode)
btnVerify.place(x=345, y=9, width=25, height=20)
// 類型提示文字
labType = tk.Label(window, text = '類型:', justify=tk.RIGHT, width=50)
labType.place(x=10, y=31, width=100, height=20)
// 類型下拉選單
comType = tt.Combobox(window, width=50, values=scope_list)
comType.place(x=110, y=31, width=150, height=20)
comType.bind("<<ComboboxSelected>>", callbackFunc3) // callbackFunc3 為類型的下拉式選單產出
//匯出檔案按鈕
btnAdd = tk.Button(window, text='匯出檔案', width=40, state=tk.DISABLED)
btnAdd.place(x=150, y=120, width=100, height=20)
// 縣市提示文字
labCity = tk.Label(window, text = '縣市:', justify=tk.RIGHT, width=50)
labCity.place(x=10, y=52, width=100, height=20)
// 縣市下拉選單
comCity = tt.Combobox(window, width=50, values=stdCity)
comCity.place(x=110, y=52, width=150, height=20)
def callbackFunc3(event):
global MAIN_URL
if comType.get() == '租屋':
MAIN_URL = "https://rent.591.com.tw/?kind=0&shType=host"
if comType.get() == '店面出租':
MAIN_URL = "https://business.591.com.tw/?type=1&kind=5"
if comType.get() == '店面出售':
MAIN_URL = "https://business.591.com.tw/?type=2&kind=5"
if comType.get() == '辦公出租':
MAIN_URL = "https://business.591.com.tw/?type=1&kind=6"
if comType.get() == '辦公出售':
MAIN_URL = "https://business.591.com.tw/?type=2&kind=6"
if comType.get() == '住辦出租':
MAIN_URL = "https://business.591.com.tw/?type=1&kind=12"
if comType.get() == '住辦出售':
MAIN_URL = "https://business.591.com.tw/?type=2&kind=12"
if comType.get() == '廠房出租':
MAIN_URL = "https://business.591.com.tw/?type=1&kind=7"
if comType.get() == '廠房出售':
MAIN_URL = "https://business.591.com.tw/?type=2&kind=7"
if comType.get() == '土地出租':
MAIN_URL = "https://business.591.com.tw/?type=1&kind=11"
if comType.get() == '土地出售':
MAIN_URL = "https://business.591.com.tw/?type=2&kind=11"
if comType.get() == '中古屋':
MAIN_URL = "https://sale.591.com.tw/"2. Python 使用者的驗證邏輯:例如使用者的裝置授權數量或是驗證碼的製作,採用 firebase 做簡易資料庫做資料比對
其實驗證的邏輯很簡單,就是把每一台電腦的MAC ADDRESS 記錄在 firebase
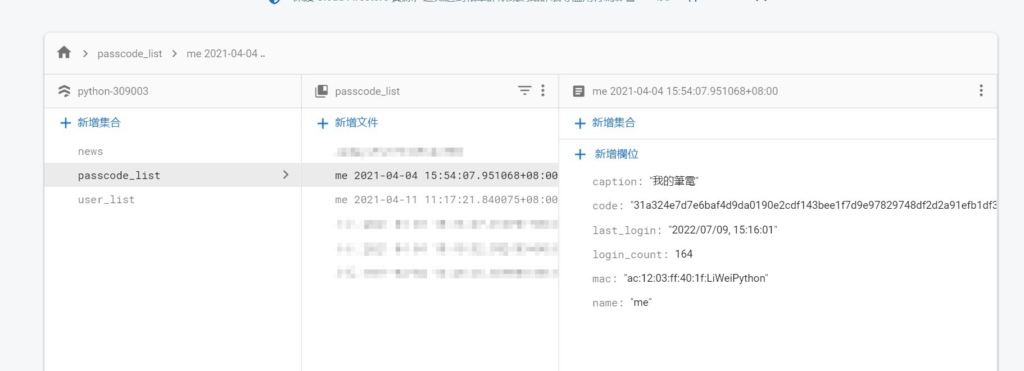
為了達到每位使用者彈性的功能設計,也將權限功能抽離出來獨立紀錄
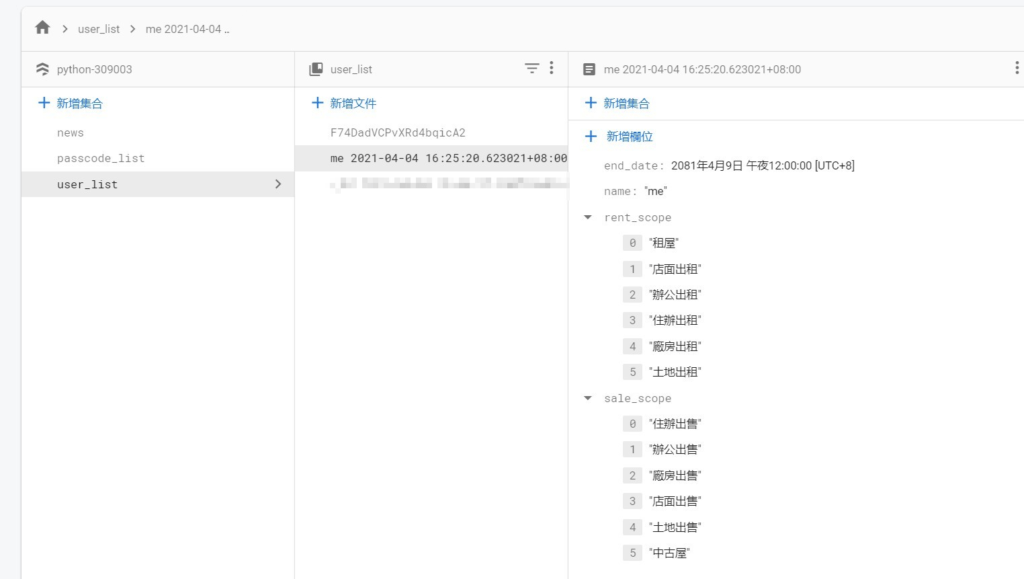
使用者的驗證邏輯部分程式:
# google firestore
import firebase_admin
from firebase_admin import credentials
from firebase_admin import firestore
# 初始化firebase,注意不能重複初始化
cred = credentials.Certificate("./serviceAccountKey.json")
firebase_admin.initialize_app(cred)
# firestore ===========================================================
pass_doc_id = []
pass_list = []
pass_name = []
login_count = []
scope_list = []
news_list = []
try:
db = firestore.client()
passcode_list_docs = db.collection(u'passcode_list').stream()
for doc in passcode_list_docs:
# print(f'{doc.id} => {doc.to_dict()}')
pass_doc_id.append(doc.id)
pass_list.append(doc.to_dict()['code'])
pass_name.append(doc.to_dict()['name'])
login_count.append(doc.to_dict()['login_count'])
USERNAME = pass_name[pass_list.index(entVerify.get())]
user_list_docs = db.collection(u'user_list').where(u'name', u'==', USERNAME).stream()
for doc in user_list_docs:
# 試用結束時間
endTime = doc.to_dict()['end_date']
# 開放權限
scope_list = doc.to_dict()['rent_scope'] + doc.to_dict()['sale_scope']
news_list_docs = db.collection(u'news').stream()
for doc in news_list_docs:
# 最新消息
news_list = doc.to_dict()['content']
except:
addInfo('驗證失敗...,請提供相關畫面聯繫作者協助')
return有關 Google firebase API對接,以後在做文章詳細介紹 serviceAccountKey.json 主要會是長這樣格式的一個JSON檔案
3. Python 網頁資料抓取:採用 selenium 將對應的物件抓取出來後用 BeautifulSoup 套件將資料取回應用
這個部分是本城是耗費時常最久的地方,要不斷的測試DOM物件的抓取是否正確,也會因網頁的更版需要做調整,所以本段僅供參考即可理解怎麼抓網頁的元素才是最重要的,另外特別一點的是我將電話圖片先下載下來放入暫存資料夾,最後的步驟會用 pytesseract 來做圖片轉文字的功能。
def getHouseData_A(url):
global now_today
request_url='https:'+str(url).strip()
res=requests.get(request_url)
if res.status_code == 200:
bs=BeautifulSoup(res.text,'html.parser')
#先宣告變數為NULL 若無撈到資料則寫入NULL
addr=''
price=''
size=''
floor=''
room_type=''
now_environment= ''
form=''
car=''
# 利用 beautfiulsoup 的 find function 利用 css selector 定位 並撈出指定資料
addr=bs.find('span',{'class':'addr'}).text
price=bs.find('div',{'class':'price'}).text.strip()
room_attrs=bs.find('ul',{'class':'attr'}).findAll('li')
for attr in room_attrs:
if attr.text.split('\xa0:\xa0\xa0')[0]=='坪數':
size=attr.text.split('\xa0:\xa0\xa0')[1]
if attr.text.split('\xa0:\xa0\xa0')[0]=='面積':
size=attr.text.split('\xa0:\xa0\xa0')[1]
elif attr.text.split('\xa0:\xa0\xa0')[0]=='樓層':
floor=attr.text.split('\xa0:\xa0\xa0')[1]
elif attr.text.split('\xa0:\xa0\xa0')[0]=='型態':
room_type=attr.text.split('\xa0:\xa0\xa0')[1]
elif attr.text.split('\xa0:\xa0\xa0')[0]=='類別':
room_type=attr.text.split('\xa0:\xa0\xa0')[1]
elif attr.text.split('\xa0:\xa0\xa0')[0]=='現況':
# print(attr.text.split('\xa0:\xa0\xa0'))
now_environment = attr.text.split('\xa0:\xa0\xa0')[1]
owner=bs.find('div',{'class':'userInfo'}).find('i').text
room_descriptions=bs.find('ul',{'class':'labelList-1'}).findAll('li')
for description in room_descriptions:
if description.text.split(':')[0]=='格局':
form=description.text.split(':')[1].replace('有陽台非於政府免付費公開資料可查詢法定用途', '')
form=form.replace('法定用途', '')
if re.sub(r"\s+", "", description.text.split(':')[0])=='車位':
car= car + ' ' + description.text.split(':')[1]
car= car.replace('管理費', '')
car= car.replace('最短租期', '')
car= car.replace('性別', '')
car= car.replace('要求', '')
person_name=bs.find('div',{'class':'avatarRight'}).findAll('i')[0].text
phone=str(bs.find('span',{'class':'num'}).text)
phone= re.sub(r"\s+", "", phone)
if len(phone) == 0 or len(phone) == 2:
phone=str(bs.find('span',{'class':'dialPhoneNum'}).text)
if len(phone) == 0 or len(phone) == 2:
phone=bs.find('span',{'class':'num'}).find('img')
# 圖片存放路徑
path = './phone_img_' + now_today + '/'
now_img_name = path + str(time.time()) + '.png'
os.makedirs(path ,exist_ok=True)
r=requests.get('http:' + str(phone["src"]), headers={'User-Agent': UserAgent().chrome})
with open(now_img_name,'wb') as f:
# 將圖片下載下來
f.write(r.content)
phone=''
return addr,price,size,floor,room_type,now_environment,car,owner,phone
else:
print('link expired:', url, res.status_code)
return 404, 404, 404, 404, 404, 404, 404
4. 彙整取回資料:將網頁上所有的資訊整理
我將所有收集到的欄位統一設定成這幾個變數 addr, price, size, floor,room_type, now_environment, car, owner, phone
def parserWeb(checkDown,df, now_today):
count_rows = 0
for i in range(int(checkDown)):
# addInfo('目前進度.... ' + str(i+1) + '/' + str(checkDown) + ' 頁')
room_url_list=[] #存放網址list
# print('browser.page_source', browser.page_source)
bs = BeautifulSoup(browser.page_source, 'html.parser')
if comType.get() in WEBTYPE_A:
titles=bs.findAll('h3') # h3 放置物件的區塊
for title in titles:
room_url=title.find('a').get('href') # 每個物件的 url
room_url_list.append(room_url)
if comType.get() in WEBTYPE_B or comType.get() in WEBTYPE_D:
titles1= bs.findAll('div', {'class':'j-house houseList-item clearfix z-hastag'})
if (len(titles1) > 0):
for title in titles1:
room_url_list.append('https://sale.591.com.tw/home/house/detail/2/' + title.attrs['data-bind'] + '.html')
titles2=bs.findAll('ul', {'class':'listInfo clearfix j-house'})
if (len(titles2) > 0):
for title in titles2:
room_url_list.append('https://sale.591.com.tw/home/house/detail/2/' + title.attrs['data-bind'] + '.html')
# ------------- GET data ------------- #
for url in room_url_list:
timestamp = random.randrange(10, 21)
addInfo('本筆停留秒數: ' + str(timestamp) + ' 目前進度.... ' + str(count_rows) + '/ 約' + str(len(room_url_list) * checkDown) + '筆')
time.sleep(timestamp)
count_rows = count_rows + 1
addr=''
price=''
size=''
floor=''
room_type=''
now_environment=''
car=''
owner=''
phone=''
try:
if comType.get() in WEBTYPE_A:
addr,price,size,floor,room_type,now_environment,car,owner,phone = getHouseData_A(url)
if comType.get() in WEBTYPE_B:
addr,price,size,floor,room_type,now_environment,car,owner,phone = getHouseData_B(url)
if comType.get() in WEBTYPE_C:
addr,price,size,floor,room_type,now_environment,car,owner,phone = getHouseData_C(url)
if comType.get() in WEBTYPE_D:
addr,price,size,floor,room_type,now_environment,car,owner,phone = getHouseData_D(url)
except:
addInfo('running code:' + printLineFileFunc())5. 製作輸出格式:採用 pandas 以及解決遇到的困難,如電話號碼欄位是圖片,我們透過 pytesseract 套件將圖片轉成文字以利輸出後透過 styleframe 輸出成 EXECL
# 準備Series 以及 append進DataFrame。值會放到相對印的column
s = pd.Series([addr, price, size, floor, room_type, now_environment, car, owner, phone, phone],
index=["地址","價格","坪數","樓層","型態","現況","車位","屋主","電話","電話辨識"])
# 因為 Series 沒有橫列的標籤, 所以加進去的時候一定要 ignore_index=True
if len(s["屋主"]) <= 0:
print('empty')
else:
df = df.append(s, ignore_index=True)
print(df)
sf = styleframe.StyleFrame(df)
if i+1 < int(checkDown):
browser.find_element_by_class_name('pageNext').send_keys(Keys.ESCAPE)
browser.find_element_by_class_name('pageNext').click()
time.sleep(1)
sf.set_column_width_dict(col_width_dict={
("地址"): 65.5,
("價格","坪數","樓層","型態","現況","車位","屋主") : 20,
("電話", "電話辨識") : 25
})
all_rows = sf.row_indexes
sf.set_row_height_dict(row_height_dict={
all_rows[1:]: 30
})
output_file_name = comType.get() + '_' +comCity.get() + '_'+ comArea.get() + now_today + '_' + str(time.time())+'.xlsx'
sf.to_excel(output_file_name,
sheet_name='Sheet1', #Create sheet
right_to_left=False,
columns_and_rows_to_freeze='A1',
row_to_add_filters=0).save()
addInfo('產出EXCEL中... ')
if comType.get() in WEBTYPE_B:
print()
else:
row = 0
img_count = 0
wb = ''
wb = load_workbook(output_file_name)
ws = wb.worksheets[0]
img_path = "phone_img_"+ now_today
dirFiles = os.listdir(img_path)
# 第 8 欄為圖片
for cell in list(ws.columns)[8]:
if cell.value is None and img_count < len(dirFiles):
# print('找到圖片 ', img_count, img_path + "/" + dirFiles[img_count])
img = openpyxl.drawing.image.Image(img_path + "/" + dirFiles[img_count]) # create image instances
# 圖片辨識
im = Image.open(img_path + "/" + dirFiles[img_count])
(x,y) = im.size #read image size
x_s = 150 #define standard width
y_s = y * x_s / x #calc height based on standard width
out = im.resize((x_s, int (y_s)),Image.ANTIALIAS) #resize image with high-quality
out.save(img_path + "/" + dirFiles[img_count])
phone_t = pytesseract.image_to_string(out)
# ws.add_image(img, 'H')
c = str(row + 1)
ws['J' + c] = ILLEGAL_CHARACTERS_RE.sub(r'', phone_t)
ws.add_image(img, 'I' + c)
img_count = img_count + 1
row = row + 1
wb.save(output_file_name)
# 清除暫存檔案
time.sleep(5)
shutil.rmtree("phone_img_"+ now_today, ignore_errors=True)
shutil.rmtree("debug.log", ignore_errors=True)
browser.quit()
addInfo('產生完成檔案:' + output_file_name)最後輸出的EXCEL檔案就會包含,”地址”,”價格”,”坪數”,”樓層”,”型態”,”現況”,”車位”,”屋主”,”電話”,”電話辨識” 這幾個欄位,可依據需求在進行調整
Python 爬蟲心得與結語
本篇完整的程式碼可以至我的 GitHub 詳閱,程式中有部分的註解說明,架構並沒有很明確的整理好閱讀起來可能會有點吃力,本程式只是將想法實踐出來還存在著許多的BUG與程式優化的地方,若有遇到甚麼問題,也歡迎在底下留言。
中文參考資料:
英文參考資料:
延伸閱讀:到我的網站其他首頁面逛逛吧!說不定會有意外的收穫呢
firebase的
passcode_list
user_list
建立資料程式好像沒有提供?
是的~建立那些資料又是另外一篇延伸的內容了,有機會我在分享